

Linux网络收发全流程理解:从网络模型到内核转换
本文最后更新于 2025-03-02,最新编辑已超过90天,注意内容时效性。
前几天面试被问到了,就正好复习总结一下Linux下操作系统对网络收发的控制。在计算机领域,层级思维无处不在,操作系统和网络也是这一点最好的体现,因此,本文将从网络模型开始探讨,包括协议栈、系统调用和中断、接收流程、发送流程等内容。
网络模型
上世纪八十年代,国际标准化组织(ISO)提出了OSI七层模型,虽然该模型分类严谨,理论影响广泛,包括我们常说的“二层”、“三层”设备都是在这一模型下的,但事实上,该模型并没有在实际开发中广泛采用,原因出其二:
- 过于复杂,部分层次实际应用中通常被合并(会话、表示)
- 来得太晚了
而我们今天常见的TCP/IP四层网络模型实际诞生于上世纪70年代美国国防部开发的ARPANET,其核心协议演变为了今天的TCP/IP协议族。出于实用需求,该模型设计非常简洁,对与网络开发来说是极为便捷清晰的,严格意义上讲并不足以概括网络的全部层次,例如数据链路层和物理层的合并。
另外,在我们的计网教材中出现了一种五层网络模型,该模型在TCP/IP的四层网络模型的基础上,拆分开了数据链据层和物理层,平衡了理论与实际,更适合在教学上分析物理接口和二层协议。
下面是几种模型分层对比:
| OSI七层网络模型 | TCP/IP四层网络模型 | 五层模型 |
|---|---|---|
| 应用层 | 应用层 | 应用层 |
| 表示层 | 应用层 | 应用层 |
| 会话层 | 应用层 | 应用层 |
| 传输层 | 传输层 | 传输层 |
| 网络层 | 网络层 | 网络层 |
| 数据链路层 | 网络接口层 | 数据链路层 |
| 物理层 | 网络接口层 | 物理层 |
插个题外话:其实这很容易让人联想到软件工程中讲到的透明性,即对于不同的场景、不同的开发层次,我们关心的内容不一样,采用的抽象模型也不一样。
网络协议栈
应用数据自应用层发出,自上而下需要加上TCP头部、IP头部和帧头帧尾,每一层头部所包含的信息各不相同,最后在物理层转化比特流(Bits)发送。

协议栈封装过程
应用层会生成按特定格式和语义定义的应用数据文件,随后调用Socket API将数据传递给传输层,然后各协议层会逐层添加协议头部信息。
传输层
确保端到端传输任务的实现(TCP/UDP,接下来的表述TCP为主),还要进行分段、端口寻址、流量控制等。传输层的具体任务如下:
- 分段数据:将应用层的数据切割为MSS大小的数据段(MSS, Maximum Segment Size, 可通过MTU算出)
- 添加TCP头部,包括源端口、目的端口、序列号、确认号等
- 可靠性处理:重传、确认、拥塞控制等
然后数据将被封装为IP数据包交给网络层。
网络层
实现逻辑寻址(IP地址)和路由选择,将数据包从源主机送到目标主机。具体任务包括:
- 添加IP头部,包括源和目的IP地址、协议类型(6-TCP,17-UDP)、TTL、分片信息
- 分片:将超过MTU(Maximum Transmission Unit,通常为1500)大小的数据包分片,并且对分片添加IP头部
- 路由选择:通过路由表确定下一跳地址
然后将IP数据包封装为数据链路帧。
数据链路层
实现物理寻址(MAC)和帧传输,处理本地网络通信,具体任务如下:
- 添加帧头:源与目的MAC地址(通过ARP获取)、类型字段(
0x0800-IPv4,0x86DD-IPv6) - 帧校验:计算CRC并添加到帧尾
最后将数据帧转换为比特流交给物理层。
封装过程实例
以发送HTTP请求为例,数据包结构如下:
[ 以太网头 | IPv4头 | TCP头 | HTTP数据 ]
- 应用层:生成HTTP请求(如
GET / HTTP/1.1) - 传输层:添加TCP头部(源端口随机分配,目的端口80)
- 网络层:添加IPv4头部(源IP为本地IP,目的IP为服务器IP)
- 数据链路层:添加以太网头部(目的MAC通过ARP解析获得)
内核关键机制和数据结构
Socket API
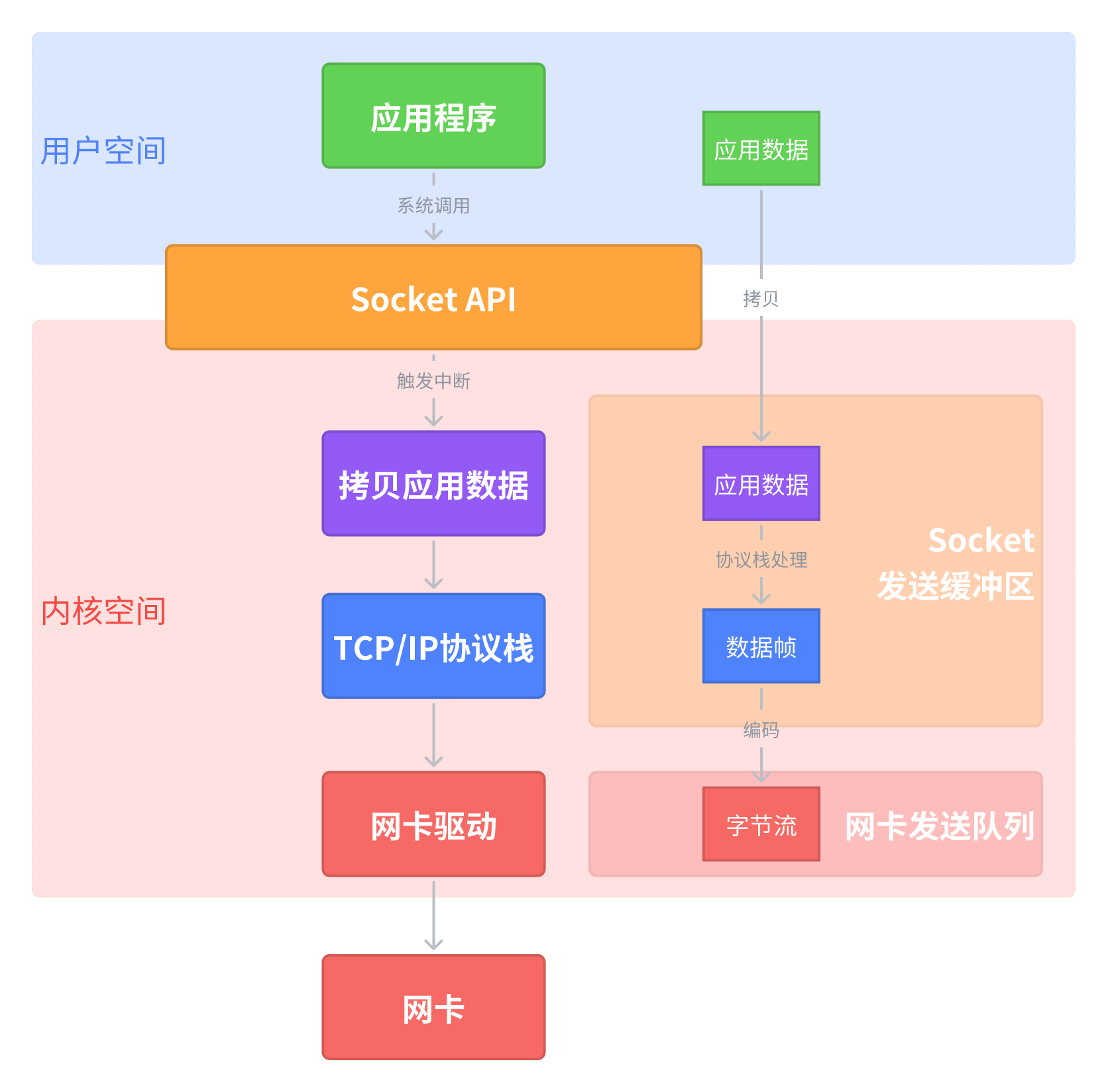
在Linux下,操作系统将内存空间划分为用户态和内核态以保证系统安全,处于用户态的应用程序无法操作内核数据或硬件(比如网卡),所以Linux提供了一系列系统调用,即Sokcet API.
Socket API是Linux对TCP/IP协议栈的封装,其本质是应用程序通过触发软中断,请求内核代为执行敏感操作。
系统中断
中断是操作系统中硬件与内核的异步协作机制,中断分为硬件中断和软中断。
硬件中断由硬件设备(比如鼠标、键盘、网卡、时钟)产生,具有突发性,CPU并不知道外部设备会在什么时候产生中断,因此硬件中断属于异步中断。中断触发后会启动中断处理程序:
- CPU暂停当前任务,执行中断处理函数
- 禁止该设备(网卡)的中断,启动软中断进行后续处理
- NAPI机制:从“中断模式”切换为“轮询模式”,减少中断次数
软中断由内核自身触发,通常是硬件中断处理程序。软中断是Linux内核中一种延迟处理机制,介于硬件中断(快速响应)和内核线程(完全异步)之间。它的设计目标是在避免硬件中断处理过长的同时,保证关键任务(如网络协议栈处理)的及时性。
核心数据结构
sk_buff:内核中管理数据包的核心结构,包含协议头指针、数据负载、路由信息等- sokcet缓冲区:
sk_write_queue管理待发送数据,sk_wmem_queued记录已提交但未确认的字节数 - Ring Buffer 环形缓冲区:DMA与协议栈之间的桥梁,直接决定数据收发的效率和稳定性。
- 接收路径:通过NAPI和GRO优化,减少中断和协议栈负载
- 发送路径:通过TSO和队列调优,提升吞吐量
网络包的发送与接收
掌握关于网络模型和Linux网络处理机制,我们便可以具体分析操作系统对网络包收发的具体处理方式。
发送数据
1. 应用程序准备数据
- 生成数据:应用程序构造需要发送的数据(例如HTTP响应),存放在可访问的用户空间,例如
char buff[1024] - 调用接口:使用
send(),write(),sendmsg()等系统调用触发数据发送
2. 系统调用与数据拷贝
- 陷入内核:执行
send()时,CPU通过syscall指令触发软中断,切换到内核态 - 拷贝数据:将用户态缓冲区的数据拷贝到内核的 Socket发送缓冲区(
sk_write_queue)。具体的拷贝行为取决于模式:- 阻塞模式:若发送缓冲区已满,进程休眠等待
- 非阻塞模式:立即返回
EAGAIN错误(缓冲区无数据)
3. 协议栈处理
- 传输层处理(TCP)
- 分段(MSS大小)
- 封装TCP头部
- 拥塞控制
- 网络层处理
- 封装IP头部
- 分片处理(超过MTU的)
- 路由选择
- 数据链路层处理
- ARP查询(若缓存没有目的IP的MAC地址)
- 封装以太网头部
4. 网卡驱动与发送
- 数据包入队:将完整的以太网帧放入网卡的发送队列(Tx Ring Buffer)
- DMA传输:网卡通过DMA(直接内存访问)从内核内存中读取数据包,避免占用CPU
- 物理信号发送:网卡将数字信号转换为物理信号(电信号、光信号、射频信号),发送到物理介质
- 发送完成中断:部分网卡在数据发送完成后触发中断,通知内核释放内存
接收数据
1. 数据包到达网卡
- DMA写入内存:网卡通过DMA将数据包写入内核的环形缓冲区(Rx Ring Buffer)
- 触发硬件中断:网卡向CPU发送硬件中断(IRQ),通知内核有新数据包到达
2. 硬件中断处理
触发中断处理程序(ISR),CPU暂停当前服务,执行网卡驱动中的中断处理函数:
- 禁用网卡中断:避免中断风暴
- 触发软中断:标记
NET_RX_SOFTIRQ软中断,后续处理交给内核线程(避免硬中断浪费CPU时间) - 切换为轮询模式(NAPI):在高流量场景下,减少中断次数
3. 软中断处理(协议栈解析)
内核线程 ksoftirqd 处理软中断任务 NET_RX_SOFTIRQ,执行以下操作:
- 从Ring Buffer读取数据包:使用
sk_buff管理数据包内存 - 解析以太网头部
- 检查MAC地址是否匹配
- 确定网络层协议(IPv4/IPv6)
- 解析IP头部
- 校验IP头校验和
- 检查目标地址是否为本机IP
- 若IP头被分片,执行分片重组
- 解析传输层头部(TCP)
- 校验序列号
- 窗口大小
- 处理拥塞控制逻辑
- 查找Socket:根据IP五元组(源IP、源端口、目的IP、目的端口、协议)在哈希表中查找匹配的Socket
- 数据存入Socket接收缓冲区:将数据包有效载荷(Payload)拷贝到Socket的
sk_receive_queue队列
4. 唤醒应用程序
通知应用程序就绪:
- 阻塞模式:若应用程序阻塞在
recv()或read()系统调用,内核将其移出等待队列,标记为可运行状态 - 非阻塞模式:直接返回数据长度或
EAGAIN错误 - Epoll事件驱动:将Socket标记为可读,通过
epoll_wait()通知应用程序
5. 应用程序读取数据
- 应用程序调用
recv()或read():- CPU执行系统调用函数触发
sys_recvfrom()切换到内核态 - 从内核的Socket缓冲区
sk_receive_queue拷贝到用户态缓冲区 - 返回实际读取的字节数
- CPU执行系统调用函数触发
零拷贝技术
首先确定,我们这里的“拷贝”关注的是CPU参与的内核空间与用户空间之间的数据搬运,这一操作浪费CPU时间,带来不必要的拷贝开销。
在传统流程下,我们使用服务器发送一个文件会经历如下过程,会经历多次数据拷贝和上下文切换:
- 磁盘 → 内核缓冲区:通过DMA完成(无需CPU)
- 内核缓冲区 → 用户缓冲区:
read()系统调用触发CPU拷贝 - 用户缓冲区 → Socket缓冲区:
write()系统调用触发CPU拷贝 - Socket缓冲区 → 网卡:通过DMA发送(无需CPU)
总拷贝次数:CPU拷贝(用户态与内核态之间)*2 + DMA*2
总上下文切换次数:read()切换2次,write()切换两次
零拷贝(Zero-Copy)技术则是通过减少或消除数据在内存中的冗余拷贝来提升网络性能的关键优化手段。其核心目标是将数据从源(如磁盘文件)直接传输到目标(如网卡或用户空间),避免CPU参与不必要的数据搬运,从而降低延迟、提升吞吐量并减少CPU占用。
详细的零拷贝实现方案不在本文展开,大致罗列关键方案如下:
- 内核旁路文件传输
sendfile():文件数据直接从磁盘通过DMA拷贝到内核缓冲区,再通过DMA从内核缓冲区发送到网卡,完全绕过用户态- 0 CPU拷贝
- 管道与Socket的零拷贝桥接
splice():利用Linux管道机制,在内核中直接将数据从文件描述符(如磁盘文件)移动到Socket,无需用户态参与- 0 CPU拷贝
- 内存映射优化
mmap() + write():将文件映射到用户态虚拟内存,直接操作内存地址,避免显式read()调用- 1 CPU拷贝








