

数据库拆分策略:分区与分库分表的实现与应用场景对比
本文最后更新于 2025-07-25,最新编辑已超过90天,注意内容时效性。
结论先行
分库分表:是一个应用架构级别的概念,意味着应用程序层面根据某些规则(如业务需求、数据量、负载均衡等)将数据水平拆分到不同的数据库或表中。分库分表的主要目的是解决数据量过大、性能瓶颈、系统扩展等问题。
-
分库:将一个大数据库拆分成多个独立的数据库实例,通常基于某些业务维度(如用户 ID、地理区域等)进行拆分。
-
分表:将某个表的数据拆分成多个子表,可以是水平拆分(按行)或垂直拆分(按列)。每个子表可以独立存储数据,并且通常也会放在同一个数据库实例中。
这些操作通常在应用程序层进行管理和路由。应用需要通过代码逻辑来决定数据的存储位置和访问方式,可能通过中间件或特定的路由算法来实现分库分表。
分区:是数据库层级提供的功能,是数据库管理系统(DBMS)的一项内建特性,用来将表的数据物理上分割为多个部分(分区)。这些分区是由数据库自动管理的,用户只需要定义分区规则(如范围分区、哈希分区等),数据库系统会负责将数据存储到相应的分区中。分区不需要额外的应用逻辑或路由,数据库会自动处理查询、插入和更新。
| 特性 | 分区 | 分库 | 分表 |
|---|---|---|---|
| 概念层级 | 数据库 | 应用 | 应用 |
| 数据存储方式 | 单个表分成多个分区(同一个数据库内) | 数据分布到多个数据库中 | 单表水平拆分成多个子表(同一个数据库内) |
| 应用层复杂性 | 较低,查询对应用透明 | 较高,应用层需要处理路由逻辑 | 较高,应用层需要处理路由逻辑 |
| 查询复杂性 | 查询针对特定分区进行优化,性能较好 | 跨库查询复杂,性能较差 | 跨表查询复杂,性能较差 |
| 事务管理 | 支持,适合单个数据库内的事务管理 | 分布式事务较为复杂,需要外部框架支持 | 跨表事务复杂,可能需要分布式事务 |
| 适用场景 | 数据量大,范围查询为主,单库内优化 | 大规模数据,需横向扩展,跨多个数据库 | 数据量大,单库内水平扩展,适合高并发 |
区别简述:在搜索中可以发现,“分库分表”通常作为一个整体概念被广泛使用,在面对高并发、海量数据的场景时,它代表的是宏观上的、架构层面的数据库拆分策略。而相对应用较少的“分区”是一种单库单表内部的数据优化手段。
分区(Partitioning)
常见数据库引擎都支持分区方式,本文描述以MySQL InnoDB为主。
MySQL数据库在5.1版本时添加了对分区的支持.MySQL数据库支持的分区类型为水平分区(指将同一个表中不同行的记录分配到不同的物理文件中)。
分区是指将一个大的数据表按某一规则分成多个物理或逻辑部分,每个部分被称为分区。MySQL分区可将同一表中不同行的记录分配到不同的物理文件(.ibd)中,从而解决大表的查询索引问题。
关于表分区后的性能表现和应用场景实际情况辨析推荐参看参考阅读1和2.
特点
-
单个数据库:不涉及多个数据库的操作可以使用分区,分区表仍然属于一个数据库,表的所有分区都在同一个数据库中
-
同一个表:分区表的各个分区虽然存储在物理上是分开的,但它们仍然是同一个表,使用相同的表结构和索引
-
透明性:查询操作对应用程序透明,查询时 MySQL 会根据分区键自动选择需要扫描的分区,避免全表扫描
分区类型
可以选择按某个字段(如 date、id 等)进行分区。
MySQL水平分区支持的分区类型包括:范围、哈希、键值、列表和复合模式,这里只详细写出范围、列表和哈希三种分区,更多分区类型参看参考阅读链接或自行搜索。
范围(RANGE)
根据某个列(如日期或整数)的取值范围,将数据划分到不同的分区。
在 RANGE 分区中,每个分区通过 VALUES LESS THAN (value) 明确设定上限,若插入值未落入任何范围且未定义 MAXVALUE 分区,则会因“无分区可归”而插入失败(ERROR 1493 (HY000): VALUES LESS THAN value must be strictly increasing for each partition),否则将自动归入包含 MAXVALUE 的分区中。
-
MAXVALUE:用于捕获超过所有定义范围的数据,是默认的“终结分区”
-
范围区间需连续且不能重叠,每条记录只能进入一个分区
列表(LIST)
LIST 分区通过 VALUES IN (value_list) 精确指定哪些离散值归入每个分区,适用于分类固定、枚举清晰的字段,如地区或状态码。
标准 LIST 分区仅支持整数(包括 NULL)。LIST COLUMNS 分区支持非整数类型值,如字符串或日期类型,并允许按列进行精确匹配。
-
每个值必须归属于某个分区,否则插入会失败
-
分区定义应覆盖所有可能值,避免遗漏导致错误
哈希(HASH)
HASH 分区通过对指定表达式进行哈希运算,将数据均匀地自动分派到指定数量的分区中,适合无明显分区规则但需平均分布的场景。
使用语法 PARTITION BY HASH(expr),其中 expr 是返回整数的表达式,通常为整型字段或计算表达式。系统会根据 expr 的哈希值自动将数据分布到预定义数量的分区中,不需要手动指定每个值所属分区。
-
若表中含有唯一键或主键,用于分区的列必须包含在这些键中,否则会导致错误
-
不支持分区裁剪(partition pruning)优化,因为分区选择是基于哈希,不可预测
-
可使用表达式(如
MOD(col, N))实现自定义分布逻辑
Demo SQL
-
建立 LIST 分区表:
CREATE TABLE random_name_library ( id INT, language VARCHAR(10), used_count INT -- other columns... ) PARTITION BY LIST (language) ( PARTITION en VALUES IN ('en'), PARTITION zh VALUES IN ('zh'), PARTITION other VALUES IN ('it', 'ja', 'hant') ); -
查看当前数据库是否启用了分区功能
show global variables like '%partition%' show plugins
分库(Sharding / Database Partitioning)
与分区不同,分库分表是应用架构级别的概念,而非数据库提供的能力。分库分表的目的是将数据按策略分散到多个节点,通过负载均衡、故障转移等方式解决数据量过大、性能瓶颈、系统扩展等问题。
特点
分库是将一个大型数据库按某些规则(如业务维度、数据范围、用户 ID 等)拆分成多个逻辑或物理独立的数据库。每个数据库存储数据的一个子集,共同组成完整的数据集。
-
水平扩展性强:通过增加数据库实例即可扩展系统能力
-
解耦和分担压力:将不同业务或数据维度分散存储,降低单库负载
-
常与分表结合使用:单表数据量大时,通常与分表一起使用形成“分库分表”
分库类型
水平分库(Sharding)
将同一表的数据按照某种规则(如用户 ID、时间范围、哈希值等)拆分到多个数据库中。例如,用户表中的用户 ID 从 1~100 万放在 db_user_0,100 万~200 万放在 db_user_1。
-
优点:数据量均衡;支持横向扩展;负载均衡
-
缺点:跨库查询复杂;事务难以控制;需要全局 ID 生成方案(比如UUID)
垂直分库(Vertical Partitioning)
根据业务模块进行拆分,将不同业务的表分布在不同的数据库中。例如用户信息表放在 db_user,订单表放在 db_order
-
优点:业务清晰、解耦;适合微服务架构。
-
缺点:存在跨库关联查询;拆分方案依赖业务理解
支持分片的中间件
分库分表涉及应用层的路由、事务管理、查询合并等问题。在现代业务框架下,已经有不少来自各大互联网厂商的成熟方案,这些中间件面对不同场景提出了不同的解决方案。
常见的数据库中间件按其架构方式又可分为Proxy和Client两种模式。
-
代理模式(Proxy):中间件通常充当数据库与应用程序之间的“中介”角色,应用程序的请求首先会通过中间件,然后由中间件将请求转发给对应的数据库实例。中间件充当数据库访问的代理,处理路由、负载均衡、分库分表等功能
-
客户端模式(Client):中间件通常直接与应用程序集成,应用程序需要在客户端配置与数据库之间的访问规则。中间件处理分库分表、路由等操作,但应用程序需要了解和管理这些操作
市场上常见的开源中间件:
| 中间件产品 | 开发厂商 | 代理模式 | 特性 |
|---|---|---|---|
| Apache ShardingSphere | Apache | Client(JDBC内嵌)/Proxy | 支持分库分表、读写分离、分布式事务、分片路由、分布式 ID 等 |
| MyCAT | MyCAT | Proxy | 基于Cobar,支持分库分表、读写分离等 |
| Cobar | 阿里巴巴 | Proxy | 兼容MySQL协议、分片扩展、高可用集群 |
| Vitess | Google (Youtube) | Client | 支持 MySQL,具备强大的自动分片能力;适合超大规模系统 |
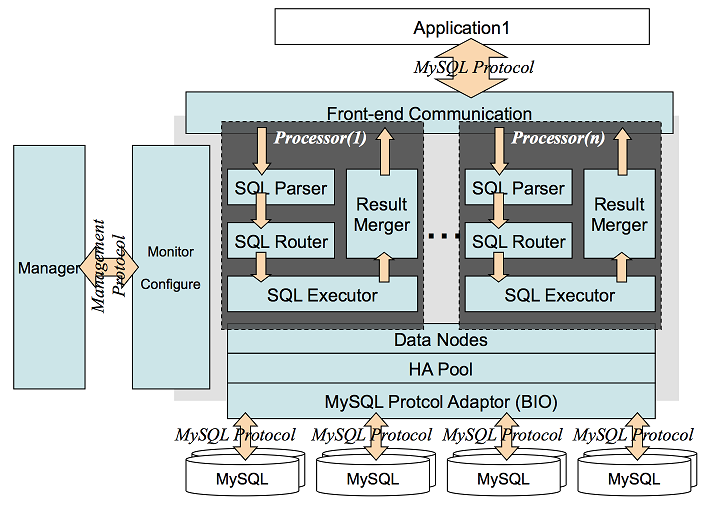
阿里Cober框架
分表(Table Sharding)
同分库类似,分表也是一种数据分片策略,分表是将一个大的数据表拆分成多个小表,每个小表存储部分数据。每个子表有相同的结构和索引,但存储不同的数据。相对地,所有子表仍在同一个数据库中。
-
高可扩展性:可以通过增加更多的子表来水平扩展系统,而不需要改变现有的数据结构或业务逻辑
-
复杂的管理:分表带来的一大挑战是跨表查询、事务管理、数据迁移等方面的复杂性
分表类型
水平分表(Sharding)
水平分表是将一个表的行数据拆分到多个子表中,每个子表存储一部分数据。适用于数据量极大且需要根据某个字段(如时间、ID、地区等)进行拆分的场景。尤其是在大规模数据的处理和查询中,能够有效分担单表的负载。
-
按范围:如根据某个字段的值(如时间、ID 范围)拆分数据
-
按哈希:根据某个字段的哈希值,将数据均匀分配到不同的子表中
-
按业务:根据不同的业务维度拆分,如按地区、用户等进行分表
垂直分表(Vertical Sharding)
定义:垂直分表是将一个表的列数据拆分到多个子表中,每个子表存储该表的一部分字段。适用于表的列数较多,但数据表的某些列访问频率较低的情况。通过将频繁访问的列单独分离,可以减少查询时的数据扫描量。
-
按功能:将用户基本信息存储在一个表,将用户的订单信息存储在另一个表
-
按访问频率:将热点数据存储在一个表,将冷数据存储在另一个表








